A subcorpus of the the larger KONTATTO corpus is now available at the EURAC Research CLARIN Centre. Browse through the Map Tasks in Italian, Trentino and Tyrolean German! Dal Negro, Silvia and Ciccolone, Simone, 2024, KONTATTO v1.0, Eurac Research CLARIN Centre, http://hdl.handle.net/20.500.12124/78.
Category: Corpus
KONTATTO fully lemmatized!

Last Summer we finally achieved our task to lemmatize this multilingual and multidialectal corpus: in the end 146719 tokens in Tyrolean German, Standard Italian, Trentino and Ladin found their direct correspondance in 6437 standardized lemmas in one of these languages. This big achievement was made possible with the help of […]
Lemmatizing KONTATTO!
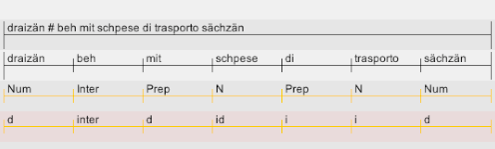
Our team is now working on the lemmatization of the corpus KONTATTO: a very challenging task, since we are dealing with a complex repertoire including Tyrolean dialect(s), Italian, Trentino and even some Ladin! Lemmas (in standard German, standard Italian and standard Gardenese) are added on a separate line which adds […]
Data transcription is on its way
Fieldworkers are transcribing their recorded data by means of the software ELAN, developed by the Max Planck Institute for Psycholonguistics. You can download ELAN here.