Languages
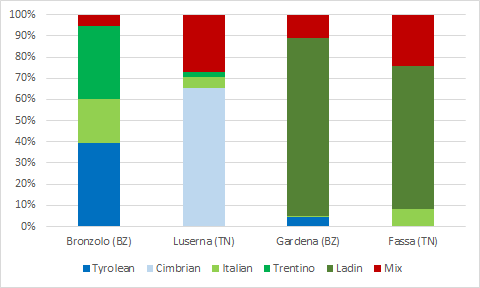
The distribution of languages in the corpus is uneven.
The chart displays the percentage of languages within each subcorpus. The annotation unit is the utterance: some utterances are monolingual and labelled for just one language, others are bi- or multilingual and are labelled as “mix”.
The chart highligts in particular two facts: 1) mixed utterances (in red) are more frequent in Luserna (Cimbrian enclave) and Fassa (Ladin area in Trentino) data; 2) the very composite nature of Bronzolo (South Tyrolean Unterland) data corresponding to a balanced and rich linguistic repertoire.
Subject expression
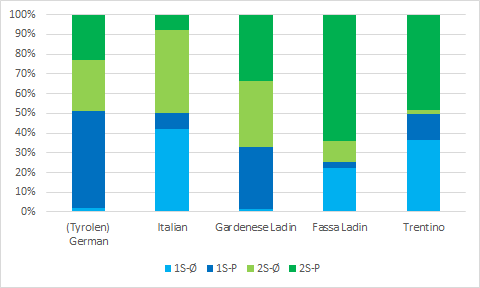
The languages in our corpus differ both on their genealogical origins (Romance and Germanic) and on various grammatical patternings. One grammatical feature that we have studied is subject expression, of which you can see data related to the first two persons of the singular.
A few facts displayed in the chart deserve some attention: 1) differently from standard German, Tyrolean allows null subjects for second persons, especially in the singular; 2) Italian is confirmed also here, in our bilingual data, a classic example of null subject language; 3) the two Ladin varieties considered here behave quite differently from each other as for this parameter. Gardenese displays a pattern that resembles that of Tyrolean whereas Fassa Ladin has a distinctive pattern that is partly similar to that of Trentino.